When Captain Picard, the commanding officer of the Starship Enterprise commanded, "Computer! get me information on...", the data is accessed simultaneously from anywhere in the galaxy and presented to him as if it were on his local computer. To do this, Captain Picard must go beyond client/server and use heterogenous distributed database management technology. Today, with Empress, you can similarly access data from many different sites with different system architectures simultaneously as if the data were on your own local system. There are reasons why you would want this type of accessing capability.
First, most organizations have offices in different locations, and quite often, applications are required to access data from multiple databases on multiple computer systems at multiple sites.
Second, due to the rapid advancement in the architecture and cost effectiveness of workstations and windowing technologies, terminals are gradually being replaced by workstations. Most workstations have a local disk and provide attractive price/performance throughput. Therefore, it makes sense to off-load data and database processing from the mainframe onto the network of workstations, and access and process data in a distributed fashion. This is commonly known as "down-sizing".
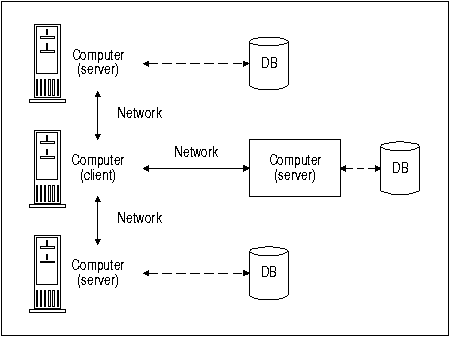
At the current level of database technology, most RDBMS operate in the client/server configuration. This configuration has been established to remove some of the database processing work from one computer and place it on others. The idea is to have the clients do all the work in displaying and validating data entry, and to have the server handle all requests for the database. Multiple client machines can then access the server machine that contains the database.
In a client/server configuration, processing is split, with two or more computers sharing the workload. This allows each machine to concentrate on a focused task.
But there are also shortcomings with the client/server configuration. For example, data is still being stored in a centralized location, so all the problems related to centralized storage still remain.
However, great improvement in the scalability, reliability and flexibility of applications can be achieved if the RDBMS client/server approach is supplemented with the new concepts of multi-server and fully-distributed databases.
This document describes how the Empress RDBMS goes beyond the conventional client/server configuration.
Empress, the heterogeneous distributed relational database management system, offers more advanced RDBMS technology than ordinary client/server. It operates not only in the client/server environment, but also in two successively richer environments: the multi-server and fully-distributed environments.
The multi-server environment can be thought of as many client/server environments. Thus, a database application running on a given client machine can access data attached to any of the servers on the network. However, even in the multi-server environment, the roles of machines as clients or servers are still distinct and unchangeable.
In a fully-distributed environment, any machine can act as a server, or as a client, or both. This is of immense importance to the database user, since it means that one can access data as if it were on the user's host machine, even if the data is inf fact physically stored on remote machines, the user's own machine, or any combination of these. The fully-distributed environment has the additional benefit of being configurable so as to optimize performance in a multi-CPU environment.
In the multiple server (multi-server) environment, data can be distributed among multiple machines. Any client machine has the ability to access one or more server machines with different or identical data. In this scenario, many possibilities exist to combat the disadvantages discussed in the client/server environment. Data can be logically grouped, so that data access traffic is balanced across the network and data is no longer limited to the storage capacity of a single machine. Data can also be replicated and mirrored across multiple server machines; in this way, data is less vulnerable to physical hardware failures. The redundancy of the data also offers multiple access points to the data.
However, the client machines in this configuration remain as client machines and cannot switch roles with the server machine. Hence, each server machine cannot directly access data from another server machine. Therefore, data transfer between server machines must be coordinated through client machines.
In this environment, each machine is able to act as a client or a server. This means local and remote databases can be accessed transparently. The diagram below shows that the fully-distributed environment incorporates the standalone, client/server and multi-server configurations. By distributing the data in an effective manner, better performance, higher survivability, and higher capacity can be achieved. For example, most used data can be placed on the machine that requests it. Data that is not used frequently by a machine can be placed elsewhere.
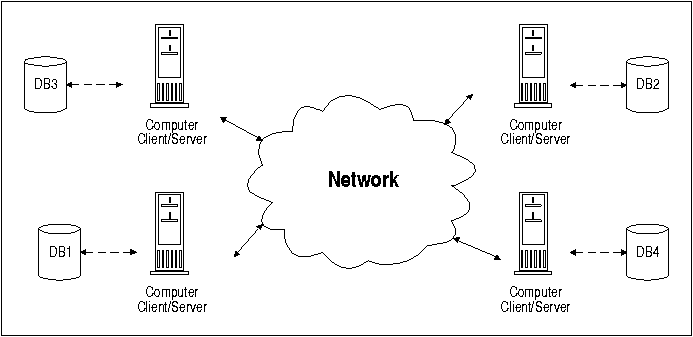
Although Empress can be configured as client/server, multi-server and fully-distributed, Empress optimized for fully-distributed configuration. This configuration allows you to:
The software technology required for a fully-distributed system is significantly more involved than client/server. In particular, one requires:
The Empress distributed database management system supports both local relations and global relations. All of the information for local relations is stored in a single table in each database. This table maintains information about objects in the database. The Global Data Dictionary contains information on the location of all databases accessed by the site.
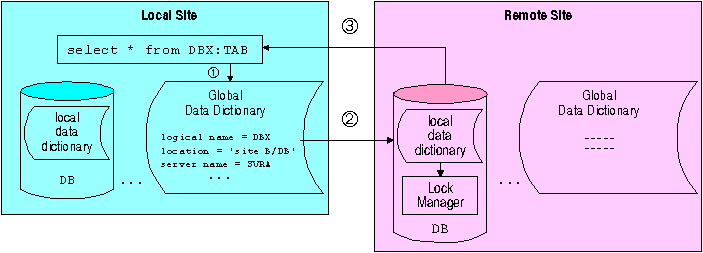
When requesting data from the remote site, Empress acquires the location of the database from the Global Data Dictionary and communicates through the Empress Server to the remote site and accesses the data through the local data dictionary as illustrated in the following diagram.
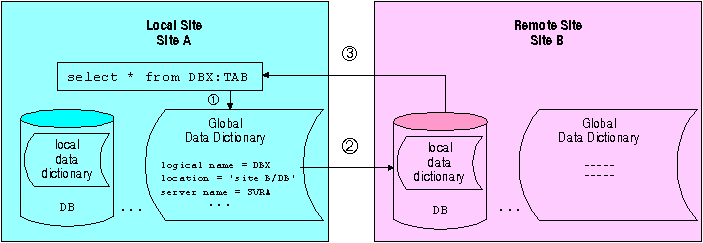
This diagram shows Site A requesting data remotely from Site B. When the query was issued from Site A, Empress at Site A understands from the Global Data Dictionary that DBX is a logical database name and that the actual location of the database is at Site B. To obtain the desired data, Site A and Site B communicate through the Database Server. In this example, Site B is a server and Site A is a client. As a result, the user can access data anywhere on the network as if the data is on the local system.
The Empress distributed database management system allows users to name their objects freely. This eliminates naming conflicts when a new site is added to an established network. Empress can handle the same attribute name from different tables, the same table name from different databases, or the same database name from different sites. This gives you total control of how an object is named on the local system. The following diagram illustrates this point.
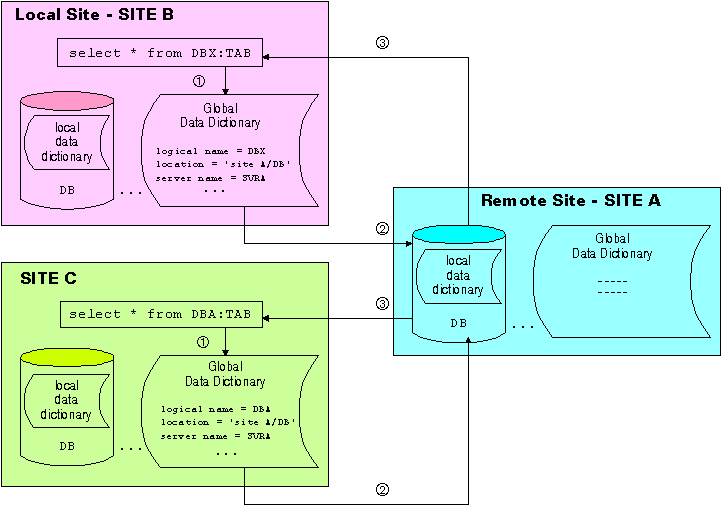
Both Site B and Site C are new additions to the network and they both happen to have a local database with the same database name of DB as the server (Site A). With Empress, not only is there no renaming required but both Site B and Site C have the freedom to choose the name they desire for the database DB at Site A (for example, DBX and DBA). As a result, users can access data anywhere on the network as if the data were on the local system and still maintain the autonomy of each site.
Locking is a mechanism to ensure the consistency of a database during multiple concurrent updates. Empress allows locking at the table, group (of records referenced), or record level. Each table has its own lock manager, which controls the locking on that table. Regardless of whether the data was requested remotely or locally, the lock manager provides the information if data is locked or places locks on the data to prevent other processes updating the same record. The following diagram illustrates that locking is controlled by the lock manager where the data resides. As a result, users can access data anywhere on the network as if that data was on the local system, and still maintain the integrity of all the data.
Empress supports the notion of a transaction. Users can run an arbitrary transaction that updates data at any number of sites and the transaction behaves exactly as if it is accessing its local database. Whenever a transaction involves more than one database, Empress uses a two-phase commit protocol to insure uniform transaction commitment or rollback. In the case of a system failure, a warm restart utility is provided to recover the databases and either uniformly commits or rolls back all unresolved transactions.
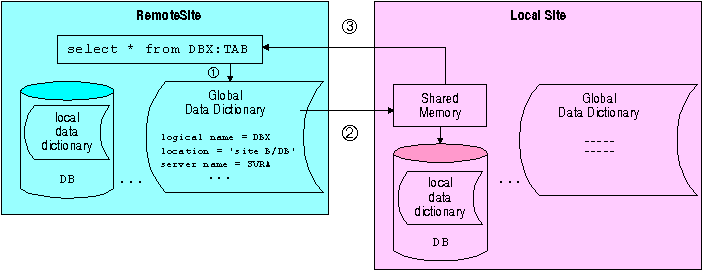
Empress takes advantage of the performance features of Shared Memory to speed up locking, on-line transaction processing, and repeated retrievals. Shared memory allows for faster allocation and de-allocation of critical resources, resulting in a much higher level of multi-user concurrency.
Shared memory is set up at the local site. In the Empress distributed environment, if data is cached into the memory, the local Empress RDBMS will access data through shared memory as illustrated in the following diagram.
Empress is a fully-distributed database management system capable of working in a heterogeneous network of computers. The purpose of a heterogeneous distributed database is to allow users to choose the best hardware for a specific function or location, and still be able to work seamlessly with other hardware architectures within the same network.
You will benefit from the heterogeneous capability of Empress applications by being able to access and use data anywhere in a network from any workstation running Empress and UNIX. Data can be stored on any machine in the network, ranging from PCs to workstations up to and including 64-bit supercomputers. The location of the data will not matter since Empress will make the data usable on any computer in the network.
The heterogenous distributed database functionality also gives MIS managers freedom to configure networks consisting of the optimum combinations of UNIX mainframes and workstations.